- 文字コードについて
*関連情報は RFC1468にありますので、そちらを参照されることをお勧めします。
(RFC1468:Network Working Group Request for Comments:1468)
- ASCII文字コード
- JIS漢字コード
- 区点コード
- SHIFT-JISコード
- EUC漢字コード
- Unicode
- 漢字コードの違い
ASCII(American National Standard Code for Infomation Interchange)コードは1962年に制定された1バイト(7ビット)文字コード(00-7F)でISO-646としてコンピュータ用の標準文字コードになっています。JIS-X0201コードはこれに半角カタカナなどを加えた1バイト(8ビット)文字コード(A0-FF)でANK(Alphabetic Numetric and Kana)と呼びます。より詳しくは、20-7EまでがASCII文字でA1-DFまでが半角カタカナ文字になります。US-ASCIIとJIS-ASCIIとでは5Cと7Eが違います。5CはUSではバックスラッシュでJISでは円記号になっています。7EはUSではチルダでJISではオーバラインになっています。いずれの問題も日本語キーボードを扱うときに戸惑うところです。(WINDOWS95の文字コード表)
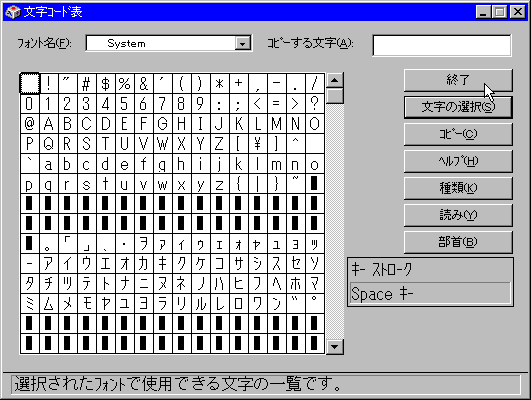
JIS(Japan Industrial Standard)漢字コードはJISで定めた文字コードでJIS-X0208で規格化された2バイトコード文字です。1978年に最初に規格が制定されてから(JIS78)、1983年(JIS83)と1990年(JIS90)に改訂されています。最初の規格を旧JIS、改訂されたものを新JISと呼ぶことがあります。第3次規格では第1水準2,965(16進コード2121-4F53、区点コード0101-4751)と第2水準3,390(16進コード5021-7426、区点コード4801-8406)が定められています。さらにJIS-X0212というJIS補助漢字5,801字が新たに定められ合計12,156字が規格化されています。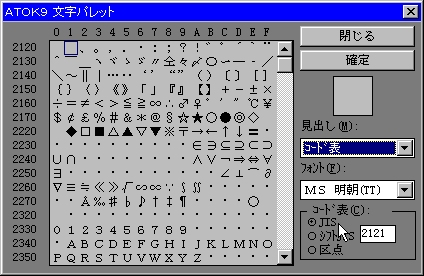
ASCII文字は7ビットコードで文字を扱っていたことから、漢字コードも7ビットJISコードが使われていました。いわゆるJUNET(Japanese University unix NETwork)コードで、ISO(International Standardization Organaization)規格ではISO-2022-JPコードです。日本語文字を7ビット2文字に符号化して表すものです。漢字とASCII文字が混ざっているときのように異なる文字セットを交換するには、エスケープシーケンスを使って、コードに割り当てる文字セットを指定するようになっています。ESC(は1バイトコード文字、ESC$は2バイトコード文字を指定しています。
| エスケープシーケンス | 文字セット |
|---|---|
| ESC(B | ASCII |
| ESC(J | JIS-X0201-1976 |
| ESC$@ | JIS-X0208-1978 |
| ESC$B | JIS-X0208-1983 |
区点コードは2バイト文字全体を1-119の区に分け、一つの区を1-94の点に分けて10進数で表しています。10進数で初心者にはわかりやすいので、ワープロなどでよく使われています。区点コードは上下2桁に区切って各数字に32を加え、それを16進数になおして並べるとJIS漢字の16進コードになります。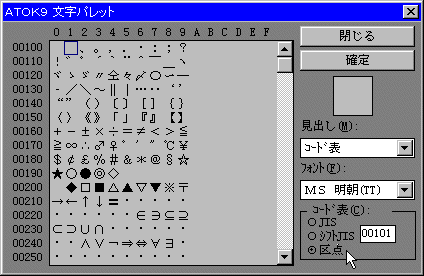
国内の大手パソコン通信ではSHIFT-JISコードが利用されます。この漢字コードは2バイトコード文字でMS漢字とも呼ばれるものです。マイクロソフト社がMS-DOSやBASICでJIS漢字コードを処理するために作った漢字コードです。JIS漢字コードと同じ2バイトコードですが、1バイトめをANK文字で使用していないエリア(0X80-0X9F,0XE0-0XFE)へシフトさせて作ったものです。これにより1バイトコード文字と2バイトコード文字が混在できる、つまり漢字コードの1バイトめは必ず0X80以上になっているので判定できるというわけです。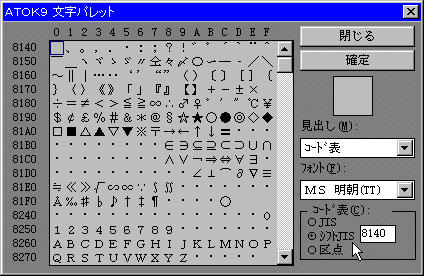
UNIXの世界では拡張UNIXコードとよばれるEUC(Extended Unix Code)コードが使われています。AT&Tで規格化されSunOSなどではEUC準拠のコード体系が使われています。日本語EUCコードはJISコードと対応しており、16進コードを上下2桁ずつに区切って各数字に16進80を加算するとEUCコードになります。つまり2121から始まるJIS漢字コードをA1A1にそっくり移動したものになっているわけで、ASCIIと共存することができます。1バイトめと2バイトめの区別さえ付けば良いのです。これは改行コードで調べることができます。ただしANK文字で半角カタカナ文字が使用している領域に重なっているため、半角カタカナ文字とは共存できません。日本語EUCではシングルシフトを使って半角カタカナの文字セットが利用できるように拡張されています。
最新の文字コードはUnicodeと呼ばれる16ビット固定長のもので1990年にバージョン1.0がリリースされ、ISOに採用されました。WIN95の一部のAPIやWindowsNTに採用されています。16ビットにすることで世界中の文字を単一のコード体系で処理しようというものです。この場合は漢字の配列順序がJIS漢字コード順にはなりません。
| JIS-X0208 では3021 |
| 区点コード では1601 |
| SHIFT-JIS では889F |
| EUCコード ではB0A1 |
| Unicode では4E9C |
- 外部とのメール交換と文字コードについて
パソコン通信では、決められたホストへ接続するため、電子メールも決まったホストを通してやりとりされます。したがって、パソコンで使われるSHIFT-JISが通るように通信路を1キャラクタを8ビットに設定してあればSHIFT-JISでそのまま電子メールの交換ができます。しかしインターネットでは、メールはいろいろな種類のマシン、主にUNIXを通ります。したがって、ISO-2022-JPにしたがって1キャラクタ7ビットに変換しないと、SHIFT-JISで書かれたメールなどは正しく読めるように伝わりません。また、半角カタカナもEUCではサポートしないこともあるので伝わらないと考えた方がよいでしょう。ここで通信環境の問題と関連が出てきます。パソコン通信を初めてする場合、通信ソフトで通信パラメータのキャラクタビット長を8ビットに指定します。これはSHIFT-JISを扱うためです。ASCIIは1バイト、JIS,SHIFT-JIS,EUCはともに2バイトで文字を表現しますが、EUCとSHIFT-JISは1バイトめの8番めの最上位ビットが「1」で、EUCは2バイトめの8番めも「1」になります。しかし、JISでは8番めは必ず「0」となっています。通信ビット長が8ビットの場合は、この8番めの違いをきちんと区別できるので問題はないのですが、外国のパソコン通信ではASCIIで情報を書くので通信パラメータに7ビットを用いています。この通信路を通ってきた場合、8ビットめはデフォルトで「0」が入ってしまいます。送るときも8ビットめは無視されます。このことから7ビット長の通信では漢字は7ビットのJISコードしか通らないことになります。そのため国内のパソコン通信はたいてい「8ビットで漢字コードはSHIFT-JIS」に通信パラメータを指定するのです。漢字を使わない外国のパソコン通信などは「7ビットでASCII文字を使う」になります。では7ビットJIS漢字なら大丈夫かというと、漢字であることを指定するエスケープシーケンスの解釈が必要になります。これが無視されると漢字として解釈できないのです。さらに、DOS,WINDOWSとUNIXとMACとでは改行コードも違っています。
| 使用機種 | 改行コード |
|---|---|
| MS-DOS,WINDOWS | 0D0A |
| UNIX | 0A |
| Macintosh | 0D |
したがって、同じ漢字コードのテキストでも機種によっては乱れたりすることも考えられます。通常は、パソコン通信なら通信ソフト、インターネットメールならメールソフトで漢字コードなどの設定をして使うことになります。これは通信経路の設定に相当します。この設定が正しければ、たいていは正常に読み書きできますが、この設定が間違っていたりすると読めないメールとなってしまいます。さらに通信経路を通ったコードが、漢字として相手に解釈されるためには、相手のマシンも送り手と同じ文字コードを解釈できるようになっていないといけません。ここで、外国のマシン環境で漢字の入ったメールを読むにはという問題が出てきます。ASCII以外の文字を使うのはなにも日本の漢字だけに限ったことではないのです。2バイトコード文字は他の国にもあります。漢字でも中国漢字と日本漢字では違います。
- コード変換について
- 符号化について
- データの圧縮(compression)について
- アーカイブ(archive)について
- 符号化圧縮展開ツールの例
*Base64関連情報は RFC989にありますので、そちらを参照されることをお勧めします。インターネットでは電子メールをやり取りする際にSMTP(Simple Mail Transfer Protocol)を使用していますが、このプロトコルでは7ビットASCIIしか通さないので、SHIFT-JIS漢字のような2バイトコード文字は正しく扱えません。そこでこの制限を回避できるようにデータ(テキストやバイナリ)を符号化して送受信できるように拡張したのがMIME(Multipurpose Internet Mail Extensions)という仕様です。最近ではmultipartといってテキスト文章と画像、サウンド、動画データを組み合わせたメールも送れるようになっています。日本語の場合はISO-2022-JP(7ビットJIS)をBase64でエンコードするものがよく使われています。簡単にいうとすべてのデータの8ビット3バイトを6ビット4バイトに振り分けて、それを通信データの7ビットに変換する方法です。
他にMIMEで使われるものにQuoted-printableというエンコードの方式があります。こちらの方は、欧米文字のように大部分がもともとASCIIで一部に非ASCII文字がある場合に有効で、ASCIIはそのまま表示が残ります。
MIME以前から使われていた方法にはuuencodeがあります。これは8ビット3バイトを6ビット4バイトへ変換する方法です。これで変換すると記号の多いテキストになります。また、パソコン通信ではISHという符号化ソフトがよく使われていました。
データが多くなると転送に時間がかかります。そこで最も頻度の多い文字から、いちばん短いビット列の文字を対応させてデータを変換していくと、データサイズを圧縮することができます。とくに通信速度が遅かった時代にはバイナリや大きなテキストなどは圧縮して送るのが普通でした。さらに、圧縮したものを符号化によってASCIIにしてしまえば、電子メールでもデータを送ることができます。圧縮に使う文字の種類は圧縮ソフトによります。よく使われる圧縮ファイルの形式には、zip,lzh,arcなどがあります。
複数のファイルを一つのファイルにまとめることをアーカイブといいます。UNIXでのtarなどがそうです。lzhやzipは圧縮機能をもつアーカイバで圧縮アーカイバということがあります。これもデータをまとめて転送するために使われています。
まず電子メールの符号化に関しては、MIMEをサポートしていれば、メールにアタッチされているマルチメディアデータも扱えるようになっています。したがって、Base64やQuoted-printableを使うにはMIMEをサポートするメールソフトを用意すればよいことになります。ただし、メールソフトの設定でMIMEを使用するにしておく必要があります。WINDOWS95ではインターネットメールのプロパティで設定できます。
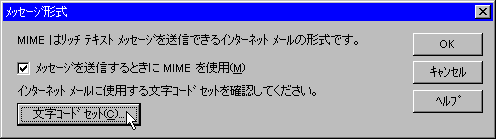
最近のパソコン用メールソフトならたいていMIMEをサポートしています。
その他の形式の場合はuuencodeとuudecodeがすべての機種で利用可能です。圧縮展開に関しては、lhaとzipが代表的です。拡張子により他にもいろいろあります。これについてはインターネットマガジンの1995/8の付録「圧縮展開ツール事典」が参考になるでしょう。
以上をまとめると電子メールを解読するのに必要な情報としては
1.漢字コード 2.符号化 3.圧縮 4.アーカイブ
の4つの情報です。このうち3と4は専用のソフトを使って圧縮展開をします。使用機種で動作するソフトを使えば解読ができます。1と2はメールサーバーやソフトの設定と関係します。WINDOWS95では、拡張文字コードセットを変更できます。
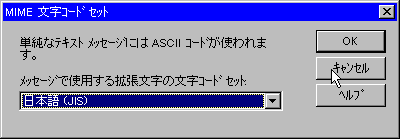
相手が対応していなかったり、サーバーで漢字コード変換をしていたり、ソフトの設定が間違っていたりすると解読ができないことがあります。
一般にテキストなら読めないメールでも正しく解釈できるように変換すればたいていは読めます。そういう変換ができるソフトを利用することをお勧めします。
WINDOWS95では例えばWZEditorなどは、EUC,JISをSHIFT-JISに変換したり、MACやUNIXのテキストも読み書きできる上にバイナリの編集も可能なので便利です。メモ帳などと違いエスケープシーケンスも正しく読みとります。読めないメールをファイルに落としてWZで読み込めば正常に読めるように自動的に変換します。WZEditorについてはhttp://www.villagecenter.co.jp/を参照して下さい。
画像やサウンドなどはたいてい拡張子で区別しますので、ファイルタイプを登録してビューワーを関連づけしておけばメールに添付してあるデータをExchangeから開くことができます。
